GitOps for multicloud resources
By Leonardo Murillo
- 20 minutes read - 4049 wordsOver the past few months, I’ve been very focused on GitOps, becoming actively involved in the GitOps Working Group as a contributor in the GitOps Principles Committee.
GitOps is a model that represents the next stage in evolution in terms of application and configuration delivery, particularly when we look at it in the context of Kubernetes.
Kubernetes with its CRDs and powerful API, is growing to become more than just a container orchestrator, rather a control plane for… basically, everything.
With that in mind, and having experimented with Crossplane for some time (see this and this), I was very intrigued about the idea of doing GitOps to manage the lifecycle of all our cloud resources. What does “all our cloud resources” mean? Everything from managed SQL databases, to message queues to any service that you can deploy on a public cloud.
I did a quick demo in Spanish for Kubernetes Community Day El Salvador (see here) on this very subject, and I left off with a feeling that I was just scratching the surface, and didn’t quite have enough time to demonstrate in detail the potential. I also wanted to do something in English to reach a wider audience.
So, here it is! In this walk through post I’ll show you what Crossplane and Flux2 are and how to get everything running and automated to deploy your cloud resources following GitOps principles. I will jump straight into the tech so, if you are not familiar with the concept of GitOps, reach out ;).
Table of Contents
- The objective
- Requirements
- Let’s get started
The objective
Our goal is to use Kubernetes native objects and workflows to provision and manage cloud resources across multiple public clouds. For this sample use case, we will run a “management” cluster, which will act as our centralized cross-cloud control plane, and we’ll provision a few sample resources across two public clouds, namely AWS and GCP, by declaring them in our repo and letting GitOps do its magic and synchronize that state across clouds.
This pattern can be extended to any cloud supported by Crossplane, including Azure, Alibaba and Equinix Metal.
Requirements
To run this full scenario you will need:
- An Ubuntu machine, running at least 20.04.
- A GitHub account with a personal access token with
repoaccess. - A Google Cloud account with billing enabled to deploy resources.
- An AWS account with a payment method or budget availabe.
I’ll attempt to keep cloud resources within the cloud provider’s free tier, but cost will depend on account specifics, please be mindful of your billing arrangement and any existing resources deployed in your account to avoid surprises.
Out of scope
We are not going to go into details as to how to satisfy the requirements above, if you need some direction in getting those in place, please use the following references:
- Multipass Instant Ubuntu VMs with a single command.
- Setting up a new GitHub Account
- Creating a Personal Access Token in GitHub
- Opening up a new Google Cloud account
- Opening up a new AWS account
Let’s get started
First, we need a Kubernetes cluster
I 💖 K3s! K3s is a certified lightweight Kubernetes distribution built for IoT and Edge, but I’ve found it incredibly convenient and reliable for all sorts of work, including local development.
Getting K3s running on your Ubuntu VM is ridiculously simple. Note that with K3s you really don’t need anything else installed, in other words, don’t worry about installing kubectl or anything like that, let K3s’ install script do all its magic.
SSH into your VM or open up a shell, and run the following command:
$ curl -sfL https://get.k3s.io | sh -
That’s it, you now have a single node Kubernetes “cluster” running. I did say ridiculously simple, did I not?
You will need to be sudoed to run kubectl commands solely because of the default permissions that K3s uses when saving the config file for the cluster (which you can find in /etc/rancher/k3s/k3s.yaml in case you want to manipulate permissions or ownership).
You can also use a configuration file or environment variable to modify some other behaviors in terms of K3s install, as well as use different installation methods. Learn more here.
You can use any Kubernetes cluster. Of course a single node K3s cluster is not highly available nor recommended for production, but everything we’ll do next will work just as well with almost any Kubernetes distro out there. To get this production ready, make sure you use a Highly Available cluster configuration.
We’ll be using our K3s install as our management cluster, which must pre-exist before we can use it to manage the rest of the infrastructure across any one of the clouds we choose to work with. Note that you can even provision other managed Kubernetes clusters from this control plane!
Now, we need Flux
A quick intro to Flux (v2)
Flux v2 and the GitOps Toolkit are great products built by Weaveworks, the company that coined the term GitOps back in 2017.
Flux v2 handles the automatic synchronization of a declared state as defined in an immutable source of truth, and the runtime state of a target Kubernetes cluster. It supports multiple technologies for source repositories (we will be using Git on GitHub), and you can choose Kustomize or Helm to package and deliver your applications.
The full list of features and support for Flux v2 is beyond the scope of this post, and considering it is currently under very active development features are also constantly changing, but please do go have a look at their documentation to learn more. We will focus only on how to get the Flux CLI installed, and get it tracking a repository to sync up against our K3s cluster, by following the official getting started docs (with some additional commentary from yours truly 😎).
GitOps is a fascinating operating model that is under very active evolution. The CNCF recently launched the GitOps Working Group, aimed at arriving at a collective definition of what GitOps means.
Bootstrapping Flux in our cluster
The Flux CLI takes care of bootstrapping the core components of the platform both into the cluster and storing their definitions inside our repository. The CLI can be installed using Homebrew on Mac or download prebuilt binaries for other architectures (Windows and Linux, both AMD64 and ARM). For simplicity, we will be using the installation script that is also available:
$ curl -s https://toolkit.fluxcd.io/install.sh | sudo bash
The script is pretty handy since it’s basically selecting the right tool to use to download the binary (between curl and wget), identifying your architecture, getting the latest version and even comparing it with the expected SHA. Running the script will place the flux binary in /usr/local/bin.
You can check it by running flux --version:
$ flux --version
flux version 0.7.7
This is something that I find particularly effective, since it gets your cluster fully GitOpsified (how do you like that term?) with basically no effort, what I mean by that is, Flux installs itself and adds all required declarations to the repo so that you get a consistent declared to running state from the very start.
As I mentioned, we are going to be using GitHub as our desired state store, in other words, where all the declarations (aka manifests) for everything that our cluster will run and manage will be stored.
The Flux2 CLI handles creating the repo, installing the applicable CRDs, operator and other components it needs to operate in the cluster, and storing all the required manifests to match that running state in your newly created repository.
The parameters to use in order to bootstrap a cluster using a personal GitHub repository vs an Organization GitHub repository are slightly different. For our scenario we will use a personal GitHub repo, but you can find details as to what needs to change for an organization repo in the official docs.
As mentioned in the requirements section you will need to set up a personal access token on your GitHub account, you will use those values as environment variables and Flux will use them to authenticate against GitHub:
export GITHUB_TOKEN=<your-token>
export GITHUB_USER=<your-username>
The variables you’ll need to define will vary depending on your source control system (eg. GitLab or Bitbucket), as well as the bootstrap parameters that you pass to the CLI. It’s important to consider that the CLI and it’s bootstrap command is only a convenient way to get a cluster managed by Flux, but manual ways exist that can be used with any git compliant version control system.
The Flux CLI includes a handy feature to validate that your cluster satisfies the minimum requirements for it to run effectively:
$ flux check --pre
► checking prerequisites
✔ kubectl 1.18.3 >=1.18.0
✔ kubernetes 1.18.2 >=1.16.0
✔ prerequisites checks passed
Now we just need to run the bootstrap command, lets look at the various parameters we need to provide, so it bootstraps our management cluster:
--owneris used to specify the name of the user or organization that owns the repository.--repositoryis the name of the repo where the state will be stored, if it doesn’t exist it will be created by the Flux CLI.--branchin which branch to push the state files once the cluster is bootstrapped.--pathdefines where in the repository you want to store the declarations for this cluster. I think it’s important to highlight a few details about what this option represents. First, you can hold desired state for multiple independent clusters in the same repo, as long as you use a different path for each. Second, you can point multiple clusters to the same path, and effectively manage the configuration of multiple identical clusters using a single desired state. Both of these alternatives are very powerful.--personalis simply used to indicate that the--ownerspecified is not an organization.
flux bootstrap github \
--owner=$GITHUB_USER \
--repository=gitopsmulticloud \
--branch=main \
--path=./clusters/management \
--personal
After you run this command, you should see output similar to the following:
► connecting to github.com
✔ repository created
✔ devs team access granted
✔ repository cloned
✚ generating manifests
✔ components manifests pushed
► installing components in flux-system namespace
deployment "source-controller" successfully rolled out
deployment "kustomize-controller" successfully rolled out
deployment "helm-controller" successfully rolled out
deployment "notification-controller" successfully rolled out
✔ install completed
► configuring deploy key
✔ deploy key configured
► generating sync manifests
✔ sync manifests pushed
► applying sync manifests
◎ waiting for cluster sync
✔ bootstrap finished
Now you should see a new namespace in your cluster called flux-system running the various flux components:
$ kubectl get all -n flux-system
NAME READY STATUS RESTARTS AGE
pod/kustomize-controller-774786db-bf9l7 1/1 Running 0 5d22h
pod/helm-controller-c65c64b89-g4db9 1/1 Running 0 5d22h
pod/notification-controller-7c8779c44-s7szm 1/1 Running 0 5d22h
pod/source-controller-74c544ddf-w6m7f 1/1 Running 0 5d22h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/notification-controller ClusterIP 10.43.190.1 <none> 80/TCP 5d22h
service/source-controller ClusterIP 10.43.238.69 <none> 80/TCP 5d22h
service/webhook-receiver ClusterIP 10.43.161.251 <none> 80/TCP 5d22h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kustomize-controller 1/1 1 1 5d22h
deployment.apps/helm-controller 1/1 1 1 5d22h
deployment.apps/notification-controller 1/1 1 1 5d22h
deployment.apps/source-controller 1/1 1 1 5d22h
NAME DESIRED CURRENT READY AGE
replicaset.apps/kustomize-controller-774786db 1 1 1 5d22h
replicaset.apps/helm-controller-c65c64b89 1 1 1 5d22h
replicaset.apps/notification-controller-7c8779c44 1 1 1 5d22h
replicaset.apps/source-controller-74c544ddf 1 1 1 5d22h
Let’s get Crossplane installed on our Cluster
Crossplane is the platform that we will use to provision and manage all of our cloud infrastructure using Kubernetes native objects. Let’s talk about some fundamental concepts that are present in Crossplane.
The full codebase that was used to produce this tutorial can be found in this repository. Of course the secrets are no longer valid 😎
Crossplane concepts
You can find a lot more in-depth details by looking at the official documentation, but we’re going to look at some of the more relevant concepts next.
Installing Crossplane
We’re going to use Helm to get Crossplane installed onto our Cluster, luckily Flux has native support for syncing Helm releases out of Helm Repositories, which is precisely the mechanism we’re looking for.
Remember how when we bootstrapped Flux onto our cluster we specified which repo we wanted to use to keep track of our cluster state? We’re going to clone a copy of that repo now, since we’ll use it to add the various components we will need to bootstrap Crossplane in our management cluster.
This is where the GitOps magic starts to show its potential
$ git clone <full-URI-to-your-repo>
Cloning into '<name-of-your-repo>'...
remote: Enumerating objects: 19, done.
remote: Counting objects: 100% (19/19), done.
remote: Compressing objects: 100% (12/12), done.
remote: Total 19 (delta 0), reused 13 (delta 0), pack-reused 0
Receiving objects: 100% (19/19), 16.34 KiB | 8.17 MiB/s, done.
The structure you’ll find inside this repository was created by the Flux bootstrap process, and should look something like this:
$ tree ./
./
├── README.md
└── clusters
└── management
└── flux-system
├── gotk-components.yaml
├── gotk-sync.yaml
└── kustomization.yaml
3 directories, 4 files
Let’s talk a little about this directory structure. When we first boostrapped Flux in the cluster, we asked it to place all the manifests that represent the state of our cluster inside /clusters/management. Flux will recursively apply anything in that path to the cluster. It is a good practice to structure the contents of the root directory for the cluster in some logical way, for example, using namespaces. As you’d imagine, what exists inside the flux-system/ subdirectory will be found inside an identically named namespace inside the cluster.
Crossplane’s default install namespace is crossplane-system, therefore we’ll create a crossplane-system/ directory inside clusters/management/ to reflect that, here’s where we’ll add all our Crossplane resources. In there, we’re going to add the following manifests:
A Namespace for Crossplane Resources
Of course, we are going to need to have a crossplane-system namespace, so that’s the first manifest we’re going to add:
---
apiVersion: v1
kind: Namespace
metadata:
name: crossplane-system
...
We’re going to save this file inside as clusters/management/crossplane-system/Namespace.yaml
Using Helm to Install Crossplane
As I mentioned, Flux includes native support for installing Helm charts, and to that end it provides two different CRDs: HelmRepository and HelmRelease. If you look at the installation instructions from Crossplane on their official documentation you’ll find something like this:
helm repo add crossplane-stable https://charts.crossplane.io/stable
helm repo update
helm install crossplane --namespace crossplane-system crossplane-stable/crossplane
From here you can identify the important pieces of information, namely repository (https://charts.crossplane.io/stable) and chart (crossplane), and you can use those values to produce your HelmRepository and HelmRelease objects as shown next:
We’re going to create a clusters/management/crossplane-system/HelmRepository.yaml file with the following contents:
---
apiVersion: source.toolkit.fluxcd.io/v1beta1
kind: HelmRepository
metadata:
name: crossplane-stable
namespace: crossplane-system
spec:
url: https://charts.crossplane.io/stable
interval: 1m
...
and a clusters/management/crossplane-system/HelmRelease.yaml file with these contents:
---
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: crossplane
namespace: crossplane-system
spec:
interval: 1m
chart:
spec:
chart: crossplane
version: '1.0.0'
sourceRef:
kind: HelmRepository
name: crossplane-stable
namespace: crossplane-system
interval: 1m
...
As you can probably tell, we’re simply creating a new instance of a HelmRepository object, and then creating a new HelmRelease specifying a specific chart and version, referencing the repository we just created.
Now, before going any further, let’s see how easy it is to get this running on our cluster, with nothing more than a commit/push, thanks to GitOps and Flux.
Our directory should look something like this now:
# tree .
$
├── crossplane-system
│ ├── HelmRelease.yaml
│ ├── HelmRepository.yaml
│ └── Namespace.yaml
└── flux-system
├── gotk-components.yaml
├── gotk-sync.yaml
└── kustomization.yaml
We already have Flux tracking our repository, so, getting this running onto our cluster is a matter of committing this and pushing it to our main branch. This is of course a simplified workflow since the objective of this post is to manage resources in the cloud, not demonstrate what the lifecycle of this type of operation should be, but if you’re interested in me covering that, please add a comment.
$ git add crossplane-system
$ git commit -m "Creating namespace and adding Crossplane"
$ git push
Now just wait a few seconds, you can watch what’s happening on your cluster with watch kubectl get all -A. In less than a minute, you should see a crossplane-system namespace show up, and pods getting created in there. Congratulations! You have just seen GitOps in action and have installed Crossplane using Helm declaratively and with a push to the repo. Pretty impressive right?
This is how your crossplane-system namespace should look like:
$ kubectl get all -n crossplane-system
NAME READY STATUS RESTARTS AGE
pod/crossplane-rbac-manager-65cd75b79d-dszdl 1/1 Running 0 2m40s
pod/crossplane-558bd75f5-w22lj 1/1 Running 0 2m40s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/crossplane-rbac-manager 1/1 1 1 2m40s
deployment.apps/crossplane 1/1 1 1 2m40s
NAME DESIRED CURRENT READY AGE
replicaset.apps/crossplane-rbac-manager-65cd75b79d 1 1 1 2m40s
replicaset.apps/crossplane-558bd75f5 1 1 1 2m40s
But we’re not done yet, now we have to use Crossplane to provision and manage our resources in the cloud.
Providers and Provider Configurations
For every Cloud vendor in which you’ll want to provision infrastructure you will need a Provider.
A Provider is installed using a CRD that specifies which package you want to use, from the various options that Crossplane makes available, one for every cloud vendor supported. Note that the Provider will also install all the applicable CRDs for any type of infrastructure that is available for provisioning in that specific cloud provider.
Let’s look at this using our both chosen clouds as examples:
Google Cloud Platform Provider
clusters/management/crossplane-system/ProviderGcp.yaml:
---
apiVersion: pkg.crossplane.io/v1
kind: Provider
metadata:
name: provider-gcp
spec:
package: crossplane/provider-gcp:master
...
Amazon Web Services Provider
clusters/management/crossplane-system/ProviderAws.yaml:
---
apiVersion: pkg.crossplane.io/v1
kind: Provider
metadata:
name: provider-aws
spec:
package: crossplane/provider-aws:master
...
The previous manifests will create two objects of type Provider: one using the crossplane/provider-gcp package named provider-gcp and another one using the crossplane/provider-aws package named provider-aws.
Important: For any provider to work, you will need to configure it with the right details for it to be able to authenticate, as well as determine any additional details that the provider might need. A ProviderConfig object will be required for every Provider and each ProviderConfig will need a corresponding Secret where authentication details are stored so that the Provider can authenticate against your cloud of choice.
The process for creating the authentication tokens necessary will vary depending on your clouds, there’s not much other than what the official documentation indicates so please simply follow this instructions to create the necessary identity that your Crossplane provider will use to interact with the Cloud’s APIs.
Google Cloud Provider Configuration
clusters/management/crossplane-system/ProviderConfigGcp.yaml:
---
apiVersion: gcp.crossplane.io/v1beta1
kind: ProviderConfig
metadata:
name: gcp-provider-config
spec:
projectID: <name-of-your-GCP-project>
credentials:
source: Secret
secretRef:
namespace: crossplane-system
name: gcp-creds
key: key
...
AWS Provider Configuration
clusters/management/crossplane-system/ProviderConfigAws.yaml:
---
apiVersion: aws.crossplane.io/v1beta1
kind: ProviderConfig
metadata:
name: aws-provider-config
spec:
credentials:
source: Secret
secretRef:
namespace: crossplane-system
name: aws-creds
key: key
...
Note that each ProviderConfig belongs to the API of each specific Provider, and you may need to pass additional properties depending on it (note for example the need to specify a projectID for the GCP provider). You can dig into the specific requirements of each CRD by looking at their documentation (aws, gcp, azure, alibaba)
You should have already created two secrets, that match the secretRef properties as defined in the ProviderConfig manifests, for reference, they should look something like this:
Credentials Secret for AWS
clusters/management/crossplane-system/SecretAws.yaml:
---
apiVersion: v1
data:
key: <details ommitted>
kind: Secret
metadata:
name: aws-creds
namespace: crossplane-system
...
Credentials Secret for GCP
clusters/management/crossplane-system/SecretGcp.yaml:
---
apiVersion: v1
data:
key: <details ommitted>
kind: Secret
metadata:
name: gcp-creds
namespace: crossplane-system
...
Now your repo should look something like this:
$ tree .
.
├── README.md
└── clusters
└── management
├── crossplane-system
│ ├── HelmRelease.yaml
│ ├── HelmRepository.yaml
│ ├── Namespace.yaml
│ ├── ProviderAws.yaml
│ ├── ProviderConfigAws.yaml
│ ├── ProviderConfigGcp.yaml
│ ├── ProviderGcp.yaml
│ ├── SecretAws.yaml
│ └── SecretGcp.yaml
└── flux-system
├── gotk-components.yaml
├── gotk-sync.yaml
└── kustomization.yaml
Let’s commit and push this into the repo, so we get our Provider and Secret in place.
$ git add ProviderAws.yaml ProviderGcp.yaml SecretAws.yaml SecretGcp.yaml
$ git commit -m "Adding cloud providers"
$ git push
At this point you should see the following resources show on your cluster:
$ kubectl get providers -A
NAME INSTALLED HEALTHY PACKAGE AGE
provider-aws True True crossplane/provider-aws:master 71s
provider-gcp True True crossplane/provider-gcp:master 71s
$ kubectl get secret -n crossplane-system
NAME TYPE DATA AGE
default-token-sv466 kubernetes.io/service-account-token 3 46h
crossplane-token-m6szw kubernetes.io/service-account-token 3 46h
rbac-manager-token-lwxsn kubernetes.io/service-account-token 3 46h
sh.helm.release.v1.crossplane.v1 helm.sh/release.v1 1 46h
sh.helm.release.v1.crossplane.v2 helm.sh/release.v1 1 46h
aws-creds Opaque 1 5m12s
gcp-creds Opaque 1 5m12s
provider-aws-bc850f4816b0-token-6vpvk kubernetes.io/service-account-token 3 4m52s
provider-gcp-20cae8e7de43-token-fbckr kubernetes.io/service-account-token 3 4m43s
Why have we not pushed the
ProviderConfigobjects yet? TheProviderConfigCRDs will not exist until after theProviderpackages get installed, which means if you push bothProviderandProviderConfigat the same time, Flux will be unable to sync. There is a way to fix this (which I learned too close to finishing this post…) usingKustomizationand thespec.dependsOnattribute. You can learn more here and I’ll probably edit this article to use that feature later on.
We are ready to push our ProviderConfig objects:
$ git add ProviderConfigAws.yaml ProviderConfigGcp.yaml
$ git commit -m "Adding our Provider Configurations"
$ git push
Now you’re good to go to start creating cloud resources using Crossplane that, using Flux and the magic of GitOps, will be provisioned on push to your Git repository!
To demonstrate, we’re going to create two SQL databases: an RDS instance in AWS and a CloudSQL database in GCP.
Creating Cloud Resources with Crossplane
As we’ve seen, Flux running in your cluster is already tracking your Git repo, and we’ve already installed and configured Crossplane with nothing other than pushing manifests to the repository. The same applies to Crossplane objects, which will effectively create resources on your available clouds.
Based on the sample manifests available in the official Crossplane docs, we are going to create one database in each of our already configured cloud providers. Note how we are specifying a providerConfigRef.name attribute which points to the appropriate ProviderConfig we created for each cloud provider:
RDS Instance Resource on AWS
clusters/management/crossplane-system/RdsInstance.yaml:
---
apiVersion: database.aws.crossplane.io/v1beta1
kind: RDSInstance
metadata:
name: rdspostgresql
namespace: crossplane-system
spec:
providerConfigRef:
name: aws-provider-config
forProvider:
region: us-east-1
dbInstanceClass: db.t2.small
masterUsername: masteruser
allocatedStorage: 20
engine: postgres
engineVersion: "9.6"
skipFinalSnapshotBeforeDeletion: true
writeConnectionSecretToRef:
namespace: crossplane-system
name: aws-rdspostgresql-conn
...
CloudSQL Instance Resource on GCP
clusters/management/crossplane-system/CloudSqlInstance.yaml:
---
apiVersion: database.gcp.crossplane.io/v1beta1
kind: CloudSQLInstance
metadata:
name: cloudsqlpostgresql
namespace: crossplane-system
spec:
providerConfigRef:
name: gcp-provider-config
forProvider:
databaseVersion: POSTGRES_9_6
region: us-central1
settings:
tier: db-custom-1-3840
dataDiskType: PD_SSD
dataDiskSizeGb: 10
writeConnectionSecretToRef:
namespace: crossplane-system
name: cloudsqlpostgresql-conn
...
Now, it’s just a matter of committing and pushing our manifests to the repo, and you will see the expected resources created by Crossplane in each of your cloud providers!
$ git add CloudSqlInstance.yaml RdsInstance.yaml
$ git commit -m "Creating SQL Database Instances in AWS and GCP"
$ git push
Note: In the case of GCP, you must have enabled the Cloud SQL API for the operation to work. The same will apply for any type of resource you want to create, the API must have been enabled before attempting to create the resource.
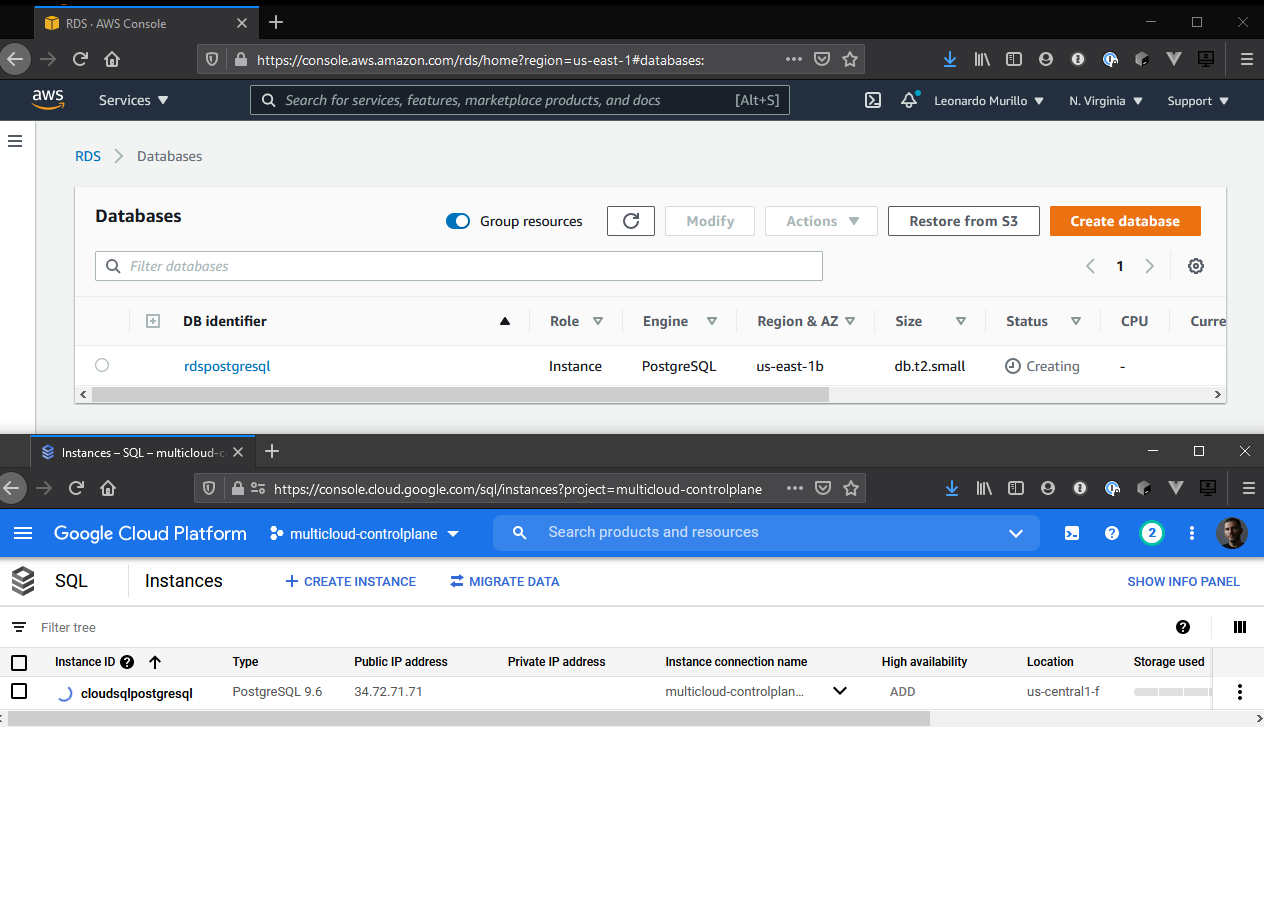
Voilà! Your databases are now spinning up!
$ kubectl get CloudSqlInstance
NAME READY SYNCED STATE VERSION AGE
cloudsqlpostgresql False True PENDING_CREATE POSTGRES_9_6 4m15s
$ kubectl get RDSInstance
NAME READY SYNCED STATE ENGINE VERSION AGE
rdspostgresql False True backing-up postgres 9.6.20 4m25s
You will also see them launching in your Cloud Provider’s consoles:
I hope this was helpful and useful! Don’t hesitate to reach out if you have any questions or comments. You can find my contact information in the upper menu and reach me on LinkedIn or Twitter.
Get notified of new experiments and articles on cloud native technologies, join my mailing list!.